There is a business process which includes printing some document and signing it by a client. However, clients often
forget to sign and cause a lot of problems and excess actions. It is needed to reduce number of unsigned documents, but
don’t use additional alerts and messages to be more user-friendly. I was asked to solve this problem and I’ve done it.
In this post I’m going to describe solution, which uses opecv+javacv. I told about this libraries in
previous post.

The problem formulation
A document is given, a client must fill some fields there like name, address and etc. The sign place is situated at the bottom of a document:

The program must detect if the sign exists or not in a scan of this document. It is possible to make not significant changes to document’s structure. Obviously, the problem may be divided in two problems:
- Finding sign area
- Analysis of this area and return if sign exists
Finding sign area
To find a sign area I need to mark it. While I was researching I tried several variants:
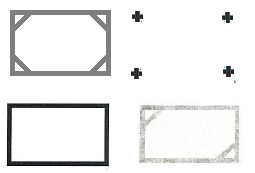
The first idea was surrounding this area by 4 crosses. I planned to find 4 crosses and investigate area between them. I tried to avoid directly detecting area with sign, because a sign may be different. However, crosses are bad idea because cross is a frequent figure, level of false detection will be very high. Then I tried to detect all rectangle with sign and it was rather better approach. There were two secrets of a success:
- Having a big positive selection with different types of sign
- Modification of a rectangle to avoid false detections. Simple rectangle is also a frequent figure.
After a few attempts I’ve found the best solution:

A rectangle highlights for a client the area for sign, doubled sides make a figure more complicated and reduce the number of false detections. To make positive selection 594 images with signs must be prepared. Here is a piece of positive selection:
I had to repeat it for several times, so I had written the util program to automate the process of creating positive selection. It accepts a scan with a lot of signs, divides it into small images (one per sign) and creates a file with positive selection for openCV training. Negative selection was made of some books about Assembler. So the negative selection is just a lot of scans of books. As a result I had 594 positive samples and 1594 negative images.
To train the algorithm I used following parameters:
opencv_traincascade.exe -data haar -vec samples.vec
-bg bad.txt -numStages 16 -minHitRate 0.99
-maxFalseAlarmRate 0.4 -numPos 550 -numNeg 1594 -w 43 -h 30
The selection was quite good, the training had taken about 3 days and was finished on 9th stage (staring from 0). The stop reason was achieving max false alarm level. Strictly speaking, the 10th stage was interrupted, but when it was interrupted, it had been working already for 20 hours. So if I had used numStages = 9, the result would have been the same and taken about 2 days.
It is advised in the documentation to use equalizeHist transformation before detection. It makes brightness and contrast better for searching. An image after this transformation looks like this:

In my case this advice sometimes helps, but sometimes harms. I mean in some cases the area wasn’t detectable after transformation, but it was before. So I decided to apply this transformation only if an area wasn’t found without it.
Actually the algorithm detects not only a sign area, it has a lot of false detections. However, all of them are smaller, that sign area. I can filter all of them by choosing the largest area. Fortunately, I’ve never faced with situation when the largest area is not appropriate sign area.
If a sign exist
It is the second part of the algorithm. It starts only if the first part has found a sign area.
The first action I decided to do is to reduce area 4 times. It allows me ignore a frame and lead the problem to finding something in white rectangle. The picture below shows that this approach is valid.
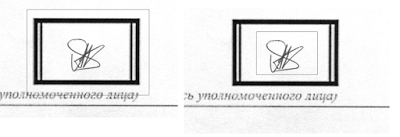
The first idea was just to count the number of dark pixels. But it is bad idea because we have different scanners, papers and nobody knows what dark pixel is. The right solution is following. As far as a picture is monochrome, a color can be represent with one integer between 0 and 255. 255 - is white, 0 - is black. Let’s calculate the standard deviation of this value inside the frame. If a sign exists, the standard deviation will be high, it means there are a lot of pixels with different from background color. My experiments showed, that optimal limit of standard deviation is 41. If it is more, it means a sign exists. The parameter is very sensitive, it even allows to filter fake signs like simple cross.
Code
import org.bytedeco.javacpp.opencv_core;
import org.bytedeco.javacpp.opencv_imgproc;
import org.bytedeco.javacpp.opencv_objdetect;
import java.nio.ByteBuffer;
import static org.bytedeco.javacpp.opencv_imgcodecs.CV_LOAD_IMAGE_GRAYSCALE;
import static org.bytedeco.javacpp.opencv_imgcodecs.imread;
import static org.bytedeco.javacpp.opencv_imgcodecs.imwrite;
import static org.bytedeco.javacpp.opencv_imgproc.rectangle;
/**
* Created by Kos on 21.08.2015.
*/
public class SignDetector {
private final int squareDeviation;
private opencv_objdetect.CascadeClassifier classifier;
/**
* Detector creation
* @param cascadeFileName - cascade file name
* @param deviationLevel - standard deviation limit
*/
public SignDetector(String cascadeFileName, int deviationLevel) {
classifier = new opencv_objdetect.CascadeClassifier(cascadeFileName);
this.squareDeviation = deviationLevel*deviationLevel;
}
/**
* Checks if a sign exists
* @param srcFName - input scan filename
* @param drawFileName - result filename (for debug)
* @return
*/
public boolean detectSign(String srcFName, String drawFileName) {
//read an image from file
opencv_core.Mat mat = imread(srcFName, CV_LOAD_IMAGE_GRAYSCALE);
// The coordinates store for detected areas
opencv_core.RectVector rectVector = new opencv_core.RectVector();
// Finding a sign area
classifier.detectMultiScale(mat, rectVector);
boolean hasFound = rectVector.size() > 0;
if (!hasFound) {
// if nothing was found lets try to transform and find again
opencv_core.Mat equalized = new opencv_core.Mat();
opencv_imgproc.equalizeHist(mat, equalized);
classifier.detectMultiScale(equalized, rectVector);
hasFound = rectVector.size() > 0;
}
if (hasFound) {
// Find the biggest area and reduce it
opencv_core.Rect rect = reduceTwice(getMaxRect(rectVector));
if (drawFileName != null) {
// draw work area and save to separate file
drawRect(mat, drawFileName, rect);
}
// sign searching in the area
return searchSign(mat, rect);
}
System.out.println("Sign place is not found");
return false;
}
/**
* Draws a rectangle and saves it to a file
* @param mat - input matrix
* @param resultFName - filename to save
* @param rect - rectangle
*/
private void drawRect(opencv_core.Mat mat, String resultFName, opencv_core.Rect rect) {
int height = rect.height();
int width = rect.width();
int x = rect.tl().x();
int y = rect.tl().y();
opencv_core.Point start = new opencv_core.Point(x, y);
opencv_core.Point finish = new opencv_core.Point(x+width, y + height);
rectangle(mat, start, finish, opencv_core.Scalar.all(0));
imwrite(resultFName, mat);
}
/**
* Sign searching in a fragment of an image
* @param mat - input matrix
* @param rect - searching rectangle
* @return
*/
private boolean searchSign(opencv_core.Mat mat, opencv_core.Rect rect) {
int x0 = rect.x();
int y0 = rect.y();
int x1 = rect.width() + x0;
int y1 = rect.height() + y0;
ByteBuffer byteBuffer = mat.getByteBuffer();
// calcution average blackness of pixels
long blackness = 0;
for (int y = y0; y <= y1; y++) {
for (int x = x0; x <= x1; x++) {
long index = y*mat.step() + x*mat.channels();
int color = byteBuffer.get((int)index) & 0xFF;
blackness += (255 - color);
}
}
float background = blackness/rect.width()/rect.height();
// calculating standard deviation
long squareDev = 0;
for (int y = y0; y <= y1; y++) {
for (int x = x0; x <= x1; x++) {
long index = y*mat.step() + x*mat.channels();
int color = byteBuffer.get((int)index) & 0xFF;
squareDev += (background - (255-color))*(background - (255-color));
}
}
squareDev = squareDev/rect.width()/rect.height();
return squareDev > squareDeviation;
}
/**
* Returns the largest rectangle
* @param rectVector
* @return
*/
private opencv_core.Rect getMaxRect(opencv_core.RectVector rectVector) {
int maxWidth = 0;
opencv_core.Rect result = null;
for (int i = 0; i <= rectVector.size(); i++) {
opencv_core.Rect currentRect = rectVector.get(i);
int width = currentRect.width();
if (width > maxWidth) {
maxWidth = width;
result = currentRect;
}
}
return result;
}
/**
* Reduces a rectangle
* @param big
* @return
*/
private opencv_core.Rect reduceTwice(opencv_core.Rect big) {
int height = big.height();
int width = big.width();
int x = big.tl().x();
int y = big.tl().y();
return new opencv_core.Rect(x+width/4, y+height/4, width/2, height/2);
}
}
Results
I’ve tested my algorithm with about hundred documents and it fails in 3 % experiments. The problem was finding a sing area, it couldn’t detect it. However a simple modification of the algorithm helped me to reduce this value to 1%.
The last modification
As I mentioned before, every scan can be handled in two states: with equalizeHist transformation and without. I decided to add 3 more transformations, so after this the list of available transformations is:
- EqualizeHist
- Rotate 180 degrees
- Rotate +5 degrees
- Rotate -5 degrees
The second transformation just give us a second attempt, because a sign is not symmetric. Small 5 degrees rotations are useful if a document is scanned with small rotation. As you know, the algorithm is not stable to small rotations.
My release version of the application firstly tries to detect an area without any transformations and then, if necessary all of these transformations and combinations of it are in series applied to the image attempt by attempt until success or full fail.