I wonder how easy a simple cluster with microservices can be created today.
Thanks to such projects like docker swarm and
kubernetes.
You don’t have to write your own soft for cluster management, most of them have been
already created. Also, these platforms unify different projects’ structures and it is
easier to support them by different engineers. Docker swarm project seems to be the easiest
and the best solution for coming into the microservices’ world. Despite the creation of a
cluster may take several minutes with a few commands, a lot of work should be done in
order to provide reliability, flexibility, and scalability of the whole application.
Docker swarm is a very powerful instrument and it provides great possibilities - our mission
is to use it in right way. In this post, I suggest one of the infinite numbers of solutions
for simple application. It should be noted, everything in this post is for education
purposes - just to get known what can be done with docker swarm.
Requirements to a cluster application
In educational purposes, let’s make a cluster for the simple CRUD application. Since we are going to implement it in microservices’ architecture, the following requirements are expected:
- Scalability (Load can be easily increased by adding new nodes)
- Reliability(Node’s fail should be almost invisible to a user)
- Transparency (We must keep all microservices under the control and don’t be perplexed when something is wrong )
- Safe and easy updating process
Application description
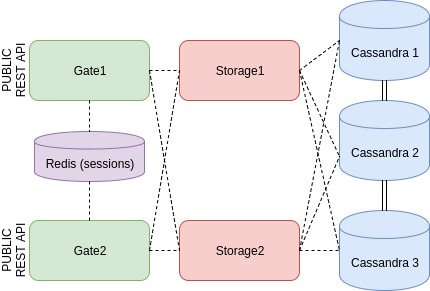
The simple CRUD application will be divided into two microservices. The first one is responsible for data storage (actually it is a bridge to a distributed database). The second one will provide REST API access to it. The distributed Cassandra database will be used as a data storage. The initial Cassandra cluster will contain three nodes, but the number can be easily increased in order to provide better performance and reliability. The REST API access will be provided by several instances of the microservice. To make available switching between them without session loss, a session will be kept in a Redis storage. To simplify I’m not going to create a Redis cluster. If Redis fails, all sessions will be lost. Let it be one of the points to improve in future.
I’m going to create several instances of the “storage” microservice and several instances of the “gate” microservice with REST API. All clients will be distributed between all “gate” instances. Every “gate” instance will request “storage” instance. Internal swarm load balancer will redirect these internal requests to provide all “storage” instances have the same load. Every storage instance will request Cassandra cluster and be tolerant if the defined number of nodes are failed.
Monitoring
Imagine, in described above system something went wrong. For example, an API user complains that output data is invalid. It is needed to see logs to understand what is going on, but there are two problems:
- If the number of instances is big, it is hard to manage with logs on every node on every service
- If a container was removed, all logs are removed too (in case there is no volume for logs).
As a conclusion, we have to use improved logging. It can be done in several ways, here is one of them. A popular stack is Logstash+Elasticsearch +Kibana. Every microservice produces several log files. Every log file is being monitored by logstash, which is located in the same docker container. When a new line appears in the log file, it is immediately parsed by lostash and sent to elasticsearch system. It provides storing all logs from the whole cluster into the one place. The Kibana gives a good user interface for reading and management logs.
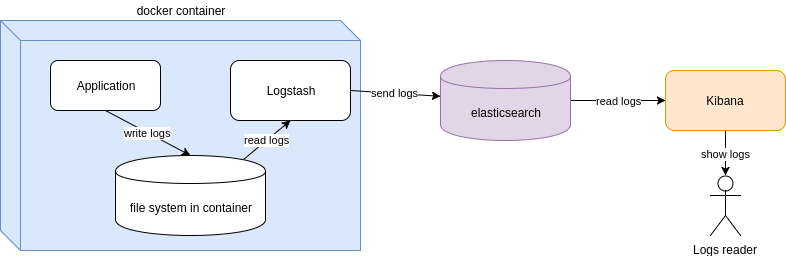
A good question is what if elasticsearch has been destroyed, but I need to see logs? There are at least two approaches about this problem:
- It is not a problem, if volumes are used for logs, all logs can be found directly in the nodes.
- It is possible to use elasticsearch cluster and copy all logs on another elasticsearch node. Also even Kibana can be doubled for reliability.
It should be noted, that I’m describing rather seldom case now. If elasticsearch is not available, but the application works, all is needed to be done is make elasticsearch working again. A bad situation is when additionally the application has broken and it is needed to see logs. Since this cluster is educational, let’s prefer the first approach - it is not a problem :).
Cluster’s structure
As you know, docker swarm is responsible for choice of hosting node, however, I’m able to set up conditions. Ideally, I can provide several nodes to the swarm, add several services to it and don’t care about where every service is. There is no difference from outside because swarm redirects requests from every node to a necessary one. It is better described in the official docker swarm documentation.
In real life, it is impossible to completely rely on the swarm. Some nodes are too weak for hosting some services, other services should be attached to corresponding special nodes due to volume exists. As a result, sometimes it is needed to tell docker swarm where to host a service. My cluster’s structure is below:
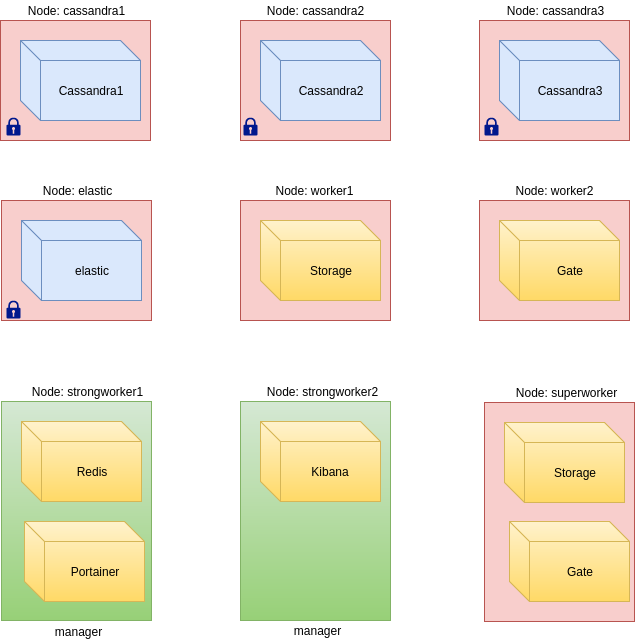
I have 9 independent nodes (VDS) in the cluster, two of them are managers. According to the description above, 9 services should be deployed at this cluster:
- Cassandra 1 service
- Cassandra 2 service
-
Cassandra 3 service
These three separate services form a Cassandra cluster inside the main cluster. The thing is that Cassandra cluster is another level cluster. Every Cassandra instance knows that it is in Cassandra cluster, but it knows nothing about the swarm cluster. It can be thought as docker packs separately every Cassandra instance into the container, names it as a services and adds it to the swarm. The swarm even doesn’t know that CassandraN services are united into own cluster.
Since all containers are stateless, volumes are used for storing data. In other words, a container will store data on the filesystem of the hosting node. This fact binds node and container, that is why I’ve prepared special nodes for hosting every Cassandra service (one the picture such nodes are marked with lock).
-
Elasticsearch service
This is one more service, that is used for storing data. There is also a special node for this service.
- Storage service
-
Gate service
These services are designed to be launched in parallel with other same instances. The main difference comparing with the cassandraN services is that every instance of the storage or gate service doesn’t know information about others. For example, one storage service can’t know the number of another instances of this service. These services are stateless, so I don’t care about hosting nodes, but docker swarm does.
- Kibana
-
Redis
According to the plan, only one instance per service is launched. Despite Redis keeps data, it is not bound to a node, as it was described before, we admit that sometimes sessions will be erased. It should be noted, that it is possible only in two cases: when redis is failed and should be relaunched or when an administrator “rebalances” cluster for getting better services per nodes distribution.
-
Portainer
Portainer is a just pretty UI for managing with a cluster.
That’s all about the description of the services. As you may see from the picture, I have 9 nodes and 4 of them are specially prepared for corresponding services. The rest services are distributed over the rest nodes. Docker provides that every instance of a service has enough resources and avoids hosting the same instances on the same node. To make the picture with nodes more clear, I use different colors for bound services and “free” services.
Docker swarm knows the parameters of every node (memory, CPU) and the demands and limits of every service. It helps to achieve better balance and to avoid failures.
All services are connected by overlay docker network. It makes them visible for other services. Those services, which have more than one instance are visible for others like one instance. The internal docker load balancer is used for requests distribution.
How is it in action
Actually, I like the result.
Here are all my nodes from the command line of the manager node:
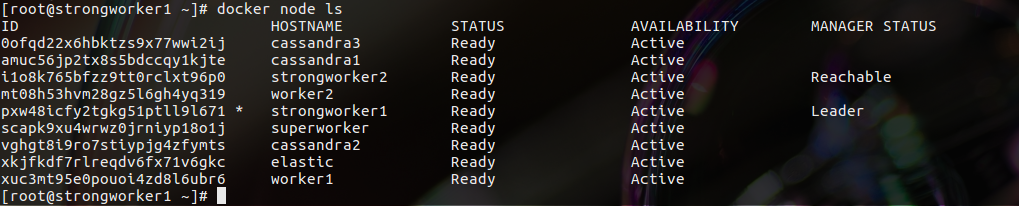
And services with the actual state:
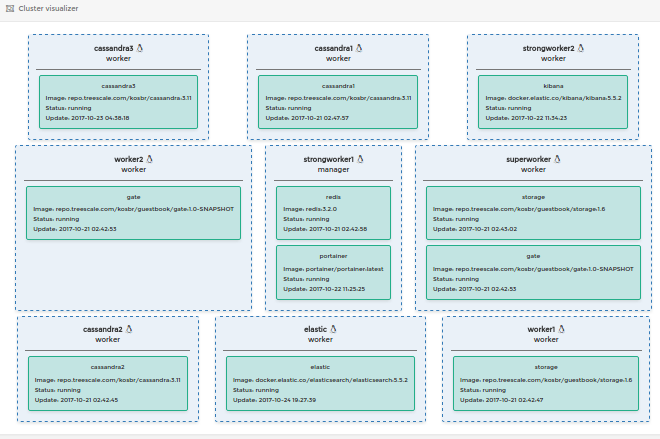
The portainer can prepare a good visualization for a cluster:
And also it provides a good UI, for example, here I can easily scale a service.
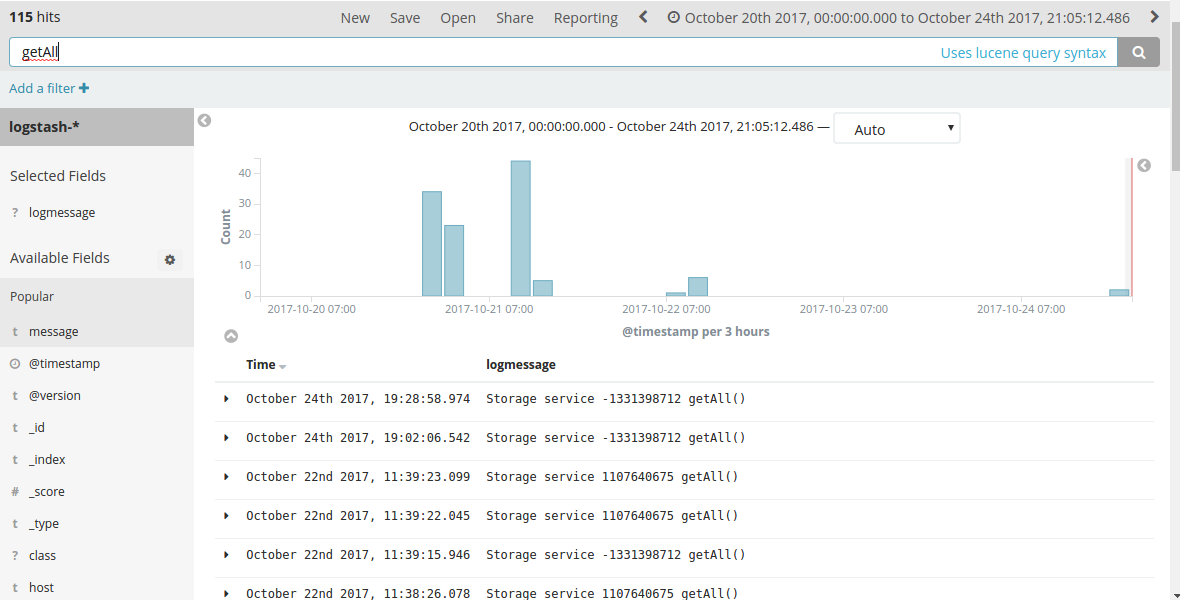
Finally, logs in Kibana. You see similar logs but from different instances. All logs can be easily filtered.
When something goes wrong
If the cluster is well balanced (bad balanced means, for example, the instances of the same services are placed on the one node) and then something happens… For example, some service or even node can be destroyed. No matter, anyway docker swarm immediately gets the state that is not equal to the wished one. If a leader manager was lost, another manager takes this role. Also, docker will try to create new instances of the services, probably on other nodes to achieve wished state again. That’s why, ideally, we should always have the additional resources in the cluster. In my case, some services can’t be recreated on other nodes - cassandra services and elastic. However, that is why I have several Cassandra services and it was explained before, that in my case the risk of elasticsearch fail is allowed (only logs are at stake).
What can be (must be) improved
Or what should be done before this cluster goes to production:
Necessary:
- Use encryption in overlay docker network (built in docker, it is needed just to switch on)
- Close all unused ports from outside by firewall on every node. All requests to open ports should be performed through SSL.
- Redis should be a cluster, probably even outside the swarm
Probably:
1.Elasticsearch should be a cluster to avoid problems with logging
It should be noted, that I used only free instruments. There are a lot commercial good instruments for monitoring cluster. Probably, it will be needed as soon as load significantly grows.
Good advantage of this technology stack
Note, that I haven’t mentioned about the internal structure of the application (storage and gate services). It means, that these applications can be created with any technology. And that is the advantage of the technology stack and architecture - we can use the best instrument for the particular problem in every microservice.
My next post is about how to deploy this cluster step by step.