Recently my friend told me about good service of Continuous Integration: http:/semaphoreci.com.
Using this service and bitbucket it is easy to create free CI system with autodeploy. Let me show how I did it.

Why do we need it?
I assume that the question “Why do we need CI?” is already answered. There is the list of advantages of such system below:
- Free.
- It doesn’t use you resources.
- It is cloud, so you are not responsible for stability.
And one constraint (unfortunately):
- Hundred builds limit per month. But it can be extended for money.
The problem description
When I was writing this post I didn’t need such system, I just wanted to try it. So I took one my old application that I had written in a hackathon and made CI to it. The git repository was on the bitbucket and the application was deployed in my server (VDS). I wanted my CI to do following steps:
- Build my project in jar
- Upload jar to my server
- Stop previous instance of the application
- Launch a new instance of the application
Solution
The semaphore service has one feature: every build uses a new absolutely clean virtual machine. That’s why I faced with two problems:
- Preparing environment before every build
- Keep artifacts
The first problem actually is not a problem, just run script before build. The second problem can be solved with the bitbucket. Look at the scheme:
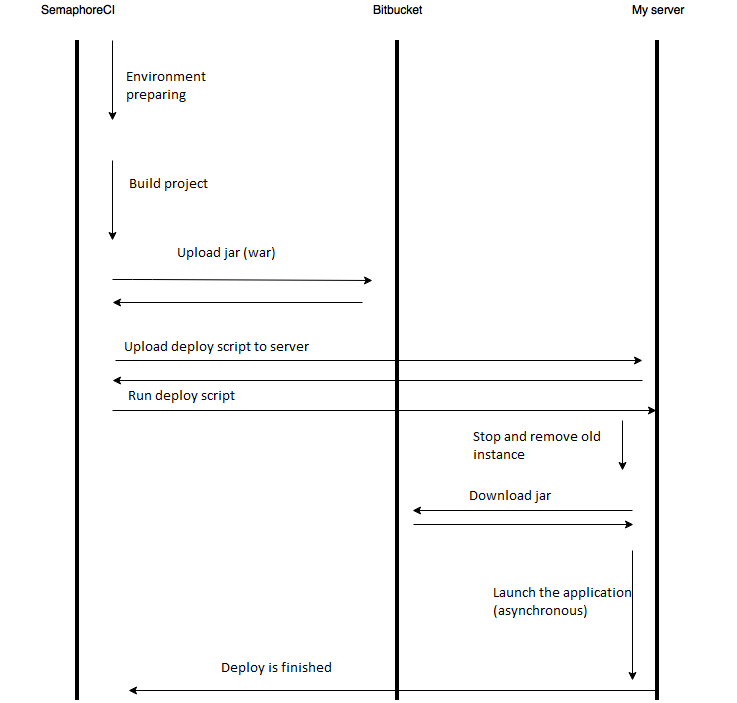
In text form the it can be described like this (step by step):
- Semaphore detects push to master (other triggers are possible).
- Semaphore creates a virtual machine for build.
- Semaphore prepares environment for build with my script.
- Semaphore builds jar.
- Semaphore uploads jar to the bitbucket’s storage using bitbucket api.
- Semaphore uploads deploy-script to the deploy server using ssh.
- Semaphore launches this script using ssh.
- The script downloads jar from the bitbucket.
- The script stops old instance of the application.
- The script launches a new version of the application.
That’s it.
Scripts
To provide step 3 I have to prepare my environment. I need only gradle.
#!/bin/bash
sudo apt-get install -y gradleStep 4 is just building the project.
#!/bin/bash
gradle clean buildTo do step 5 I need to add build number to the jar’s name and upload it:
#!/bin/bash
. ./gradle.properties
OLD_BUILD_FILE=build/libs/$baseProjectName-$baseVersion-RELEASE.jar
NEW_BUILD_FILE=build/libs/$baseProjectName-$baseVersion-RELEASE-build-$SEMAPHORE_BUILD_NUMBER.jar
# rename jar
mv $OLD_BUILD_FILE $NEW_BUILD_FILE
# upload it to the bitbucket
echo Build is uploading...
curl -s -u $BB_USER:$BB_PASS -X POST $BB_API -F files=@$NEW_BUILD_FILE
echo Build is uploadedHere is my gradle.properties which contains project’s name and version.
baseVersion=1.2
baseProjectName=someProjectI’ve written two scripts: deploy.sh and kill.sh. Both of them must be launched in server. First one is responsible for deploy and the second one is responsible for stopping old instance and deleting old jar. The script below provides uploading these two scripts to my server.
#!/bin/bash
. ./gradle.properties
SCRIPT_DIR="~/someProject"
BUILD_FILE=$baseProjectName-$baseVersion-RELEASE-build-$SEMAPHORE_BUILD_NUMBER.jar
# remove deploy.sh script from previous build
echo Removing old deploy.sh ...
ssh -o StrictHostKeychecking=no $SERVER_USER@$SERVER_HOST rm $SCRIPT_DIR'/'deploy.sh
# remove old kill.sh script from previous build
echo Removing old kill.sh ...
ssh -o StrictHostKeychecking=no $SERVER_USER@$SERVER_HOST rm $SCRIPT_DIR'/'kill.sh
# copy new deploy.sh to server
echo Copy new deploy.sh to server...
scp -o StrictHostKeychecking=no deploy.sh $SERVER_USER@$SERVER_HOST:$SCRIPT_DIR
# copy new kill.sh to server
echo Copy new kill.sh to server...
scp -o StrictHostKeychecking=no kill.sh $SERVER_USER@$SERVER_HOST:$SCRIPT_DIR
# remote run deploy.sh on the server and pass it some params
echo Run delpoy.sh ...
ssh -o StrictHostKeychecking=no $SERVER_USER@$SERVER_HOST bash $SCRIPT_DIR'/'deploy.sh -u $BB_LOGIN -p $BB_PASSWORD -h $BB_DOWNLOADS -b $BUILD_FILE -q 8082
echo Finish deployingObviously the deploy.sh and kill.sh scripts are seldom changed, but I left such possibility for flexibility. Also the deploy.sh script accepts bitbucket credentials, build filename and launch port to be more flexible.
The deploy.sh script:
#!/bin/bash
# Stop old instance and remove old jar
bash $SCRIPT_DIR'/'kill.sh
# Load new jar from the bitbucket
echo "Loading build..."
wget --user $BB_USER --password $BB_PASSWORD $BB_URL'/'$BUILD_FILE -O $DEPLOY_DIR'/'$BUILD_FILE
echo "Running new build..."
# Run new instance
nohup java -jar $DEPLOY_DIR'/'$BUILD_FILE --server.port=$APP_PORT > $DEPLOY_DIR/ak.log 2>&1&
# Create kill.properties file, which will be used for deleting this instance
echo 'OLD_PID='$! > $SCRIPT_DIR'/'kill.properties
echo 'OLD_BUILD_FILE='$BUILD_FILE >> $SCRIPT_DIR'/'kill.properties
echo 'DEPLOY_DIR='$DEPLOY_DIR >> $SCRIPT_DIR'/'kill.properties
exit 0The kill.sh script:
#!/bin/bash
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
# Check if kill.properties exist
if [ ! -f $SCRIPT_DIR'/kill.properties' ]
then
echo "Nothing to kill"
exit 0
fi
# Load properties
. $SCRIPT_DIR'/kill.properties'
# kill process
echo 'kill pid ' $OLD_PID
kill $OLD_PID
# waiting until the process is killed
echo "Waiting for stop..."
while [ -d /proc/$OLD_PID ]; do
sleep 1
done
# deleting old jar and logs
echo 'Deleting old build...'
rm $DEPLOY_DIR'/'$OLD_BUILD_FILE
rm $DEPLOY_DIR'/somelog.log'
echo 'Old build was deleted'kill.properties file is some kind of mail from current deployed to next version killer. It contains PID of current process and the name of old jar.
Conclusion
To investigate what I’ve done I collected statistics of deploy time and I’d like to present the best and the worst build:
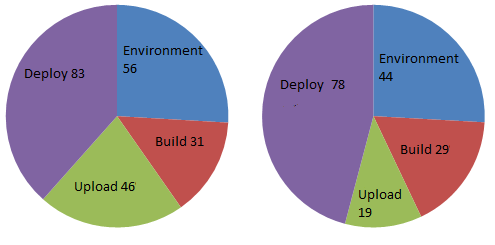
Left one is the worst, right one is the best. The measure unit is seconds. The biggest part if time is spent on deploy (running deploy.sh). And the biggest part of this time my server downloads jar from the bitbucket. My build’s size is about 40 Mb.
You can see how strongly the duration of jar download changes. It means the connection speed between the semaphore and the bitbucket is volatile. Also it is seen that about 25% of whole time is spent on preparing virtual machine. The semaphore service has some internal cache that helps to decrease duration of this step. The build time (with downloading dependencies) is very stable.
Maybe my system seems to be too complicated, but it is flexible. It is possible to implement all what you want using semaphore CI. I definitely will use it in small non-commercial projects when I need to save money and resources.